
Using Ollama to Run LLMs Locally
Tired of cloud-based AI services that compromise your privacy and rack up subscription costs? Discover how to run powerful language models directly on your own computer with Ollama. This comprehensive guide will show you how to unlock local AI capabilities, giving you complete control over your data and interactions—no internet connection required. By Eric Van de Kerckhove.
Large Language Models (LLMs) have transformed how we interact with AI, but using them typically requires sending your data to cloud services like OpenAI’s ChatGPT. For those concerned with privacy, working in environments with limited internet access, or simply wanting to avoid subscription costs, running LLMs locally is an attractive alternative.
With tools like Ollama, you can run large language models directly on your own hardware, maintaining full control over your data.
Getting Started
To follow along with this tutorial, you’ll need a computer with the following specs:
- At least 8GB of RAM (16GB or more recommended for larger models)
- At least 10GB of free disk space
- (optional, but recommended) A dedicated GPU
- Windows, macOS, or Linux as your operating system
The more powerful your hardware, the better your experience will be. A dedicated GPU with at least 12GB of VRAM will allow you to comfortably run most LLMs. If you have the budget, you might even want to consider a high-end GPU like a RTX 4090 or RTX 5090. Don’t fret if you can’t afford any of that though, Ollama will even run on a Raspberry Pi 4!
What is Ollama?
Ollama is an open-source, lightweight framework designed to run large language models on your local machine or server. It makes running complex AI models as simple as running a single command, without requiring deep technical knowledge of machine learning infrastructure.
Here are some key features of Ollama:
- Simple command-line interface for running models
- RESTful API for integrating LLMs into your applications
- Support for models like Llama, Mistral, and Gemma
- Efficient memory management to run models on consumer hardware
- Cross-platform support for Windows, macOS, and Linux
Unlike cloud-based solutions like ChatGPT or Claude, Ollama doesn’t require an internet connection once you’ve downloaded the models. A big benefit of running LLMs locally is no usage quotas or API costs to worry about. This makes it perfect for developers wanting to experiment with LLMs, users concerned about privacy, or anyone wanting to integrate AI capabilities into offline applications.
Downloading and Installing Ollama
To get started with Ollama, you’ll need to download and install it on your system.
First off, visit the official Ollama website at https://ollama.com/download and select your operating system. I’m using Windows, so I’ll be covering that. It’s very straightforward for all operating systems though, so no worries!
Depending on your OS, you’ll either see a download button or an installation command. If you see the download button, click it to download the installer.

Once you’ve downloaded Ollama, install it on your system. On Windows, this is done via an installer. Once it opens, click the Install button and Ollama will install automatically.

Once installed, Ollama will start automatically and create a system tray icon.
![]()
After installation, Ollama runs as a background service and listens on localhost:11434 by default. This is where the API will be accessible for other applications to connect to. You can check if the service is running correctly by opening http://localhost:11434 in your web browser. If you see a response, you’re good to go!

Your First Chat
Now that Ollama is installed, it’s time to download an LLM and start a conversation.
OLLAMA_DATA_PATH environment variable to point to the desired location. This is especially useful if you have limited disk space on your drive.To do this, use the command
setx OLLAMA_DATA_PATH "path/to/your/directory" on Windows or export OLLAMA_DATA_PATH="path/to/your/directory" on Linux and macOS.
To start a new conversation using Ollama, open a terminal or command prompt and run the following command:
ollama run gemma3
This start a new chat session with Gemma3, a powerful and efficient 4B parameter model. When you run this command for the first time, Ollama will download the model, which may take a few minutes depending on your internet connection. You’ll see a progress indicator as the model downloads Once it’s ready you’ll see >>> Send a message in the terminal:

Try asking a simple question:
>>> What is the capital of Belgium?
The model will generate a response that hopefully answers your question. In my case, I got this response:
The capital of Belgium is **Brussels**.
It's the country's political, economic, and cultural center. 😊
Do you want to know anything more about Brussels?
You can continue the conversation by adding more questions or statements. To exit the chat, type /bye or press Ctrl+D.
Congratulations! You’ve just had your first conversation with a locally running LLM.
Where to Find More Models?
While Gemma 3 might work well for you, there are many other models available out there. Some models are better for coding for example, while others are better for conversation.
Official Ollama Models
The first stop for Ollama models is the official Ollama library.

The library contains a wide range of models, including chat models, coding models, and more. The models get updated almost daily, so make sure to check back often.
To download and run any of these models you’re interested in, check the instructions on the model page.
For example, you might want to try a distilled deepseek-r1 model. To open the model page, click on the model name in the library.

You’ll now see the different sizes available for this model (1), along with the command to run it (2) and the used parameters (3).
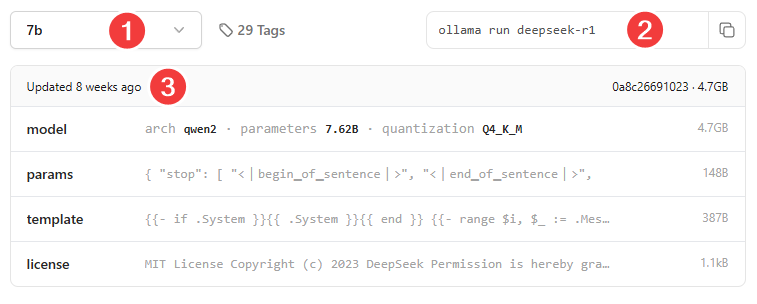
Depending on your system, you can choose a smaller or a smaller variant with the dropdown on the left. If you have 16GB or more VRAM and want to experiment with a larger model, you can choose the 14B variant. Selecting 14b in the dropdown will change the command next to it as well.

Choose a size you want to try and copy the command to your clipboard. Next, paste it into a terminal or command prompt to download and run the model. I went with the 8b variant for this example, so I ran the following command:
ollama run deepseek-r1:8b
Just like with Gemma 3, you’ll see a progress indicator as the model downloads. Once it’s ready, you’ll see a >>> Send a message prompt in the terminal.

To test if the model works as expected, ask a question and you should get a response. I asked the same question as before:
>>> What is the capital of Belgium?
The response I got was:
<think>
</think>
The capital of Belgium is Brussels.
The empty <think> tags in this case are there because deepseek-r1 is a reasoning model, and it didn’t need to do any reasoning to answer this particular question. Feel free to experiment with different models and questions to see what outcomes you get.